
This case study describes the process, the challenges and the outcomes of a historical data migration project. This project consisted of migrating data from two Wonderware (Industrial SQL) Historians to a single OSISoft PI Historian. The PI Historian had replaced the InSQL Historians, but this resulted in valuable historical data being split among three historians.
![]()
By migrating the historical data from the two InSQL Historians to the PI Historian, all the historical data became available in the PI Historian, and the two InSQL Historians could be decommissioned.
We will refer to the 2 InSQL Historians as ‘InSQL 1’ and ‘InSQL 2’. These two historians had the following properties:
InSQL 1:
- Time span: 4 years and 7 months.
- No. of Tags: approx. 23 000.
InSQL 2:
- Time span: 1 year and 11 months.
- No. of Tags: approx. 40 000.
The InSQL Historians not only overlapped in time but also had common tags which extracted their data from the same source. The tags in the PI Historian are a superset of the union of the tags in the two InSQL Historians. However, for many tags, the name in PI was different from the corresponding tags in InSQL 1 and/or InSQL 2.
The results of the migration are summarised in the figure below. The two plots show historical data from InSQL 1 and the migrated data in PI for a single tag covering one day. These plots are derived from the migration analysis results (more on which see below).
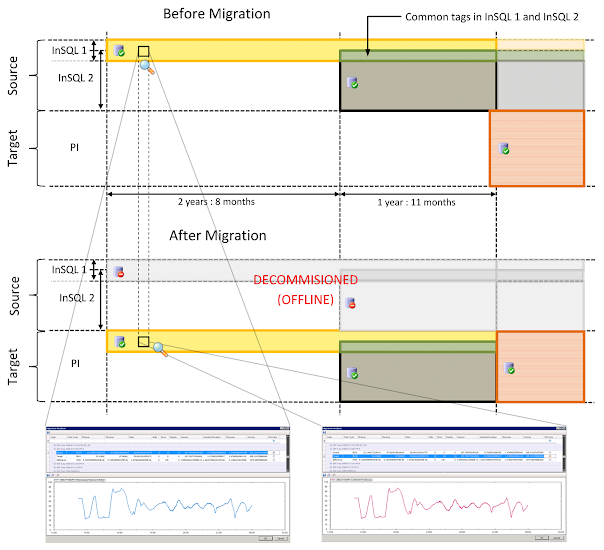
The result of migrating historical data from InSQL 1 and InSQL 2 to PI.
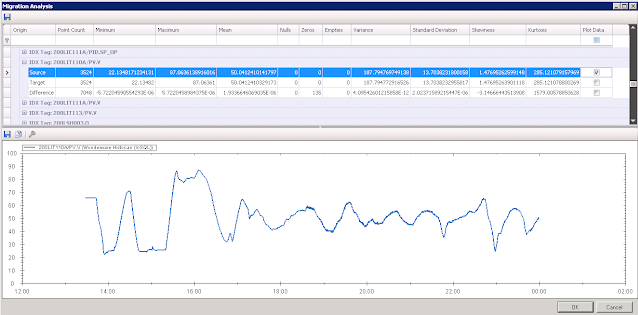
Migration Analysis: Source (InSQL) Plot.
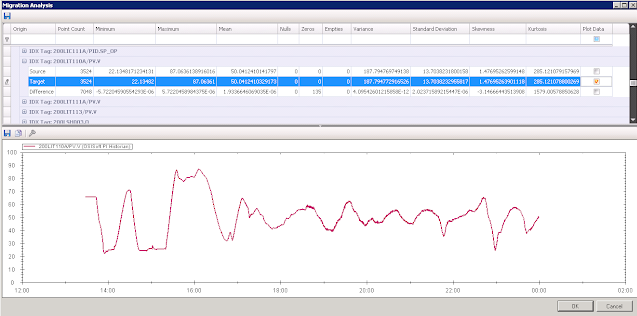
Migration Analysis: Target (PI) Plot
The migration process consisted of the following steps:
- Synchronisation of tag configurations: This consists of linking tags from the source historians (InSQL 1 and InSQL 2) to the corresponding tags in the target historian (PI). This step is particularly important for tags whose names differ in the source and target historians.
- Import tag configurations and their synchronisation into Tag Manager: By using Tag Manager, this otherwise manual process is greatly simplified.
- Create the Migration Jobs: Migration Jobs are responsible for the actual migration and run as services. A Migration Job is characterised by source and target historians, a tag list (imported from Tag Manager), and start and end times. Migration jobs are subdivided into batches, which are the smallest repeatable units of a migration job. The migration was completed using 6 jobs (4 for InSQL 1 and 2 for InSQL 2) and each batch had a time range of one day.
- Analysis and verification: After a batch completes data migration, there is an option of running an analysis step. During this step, data from the source and the target are extracted and compared. Based on the difference between the source and target data, thresholds can be set to identify potentially problematic cases. Because of this, the migration was not merely a blind process. The results of the migration were verified.
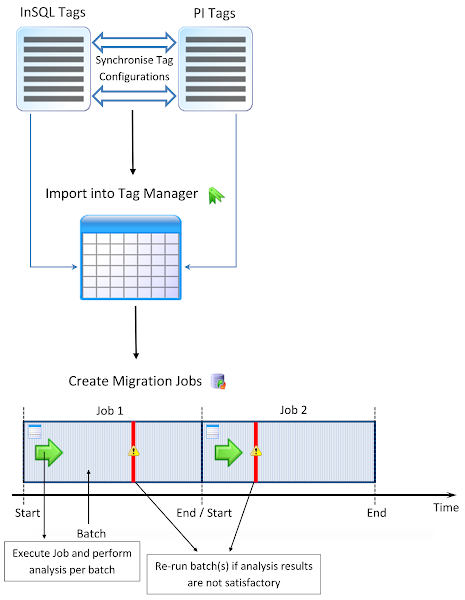
Summary of the migration process
The migration was executed on 6 virtual machines (VMs) running Windows Server 2003 R2. Three VMs were used per migration job (one for the InSQL Historian Server, one for the PI Historian Server and one for IDX 8 and Migration Job service). This meant that two Migration Jobs could be run in parallel.
The time it took to complete the entire migration process is summarised as follows:
- Tag configuration synchronisation and importing to Tag Manager (InSQL 1 and InSQL 2): 2 weeks.
- Executing the migration jobs (including analysis):
- InSQL 1 (23,000 tags, 4 years and 7 months): 2 weeks.
- InSQL 2 (40,000 tags, 1 year and 11 months): 5 days.
One of the challenges encountered was that certain tags had an incorrect data type in the InSQL Historian. This meant that the data types did not match in InSQL and PI. This required that the data for these tags not be migrated as is, but that a ‘processing’ step be included during the migration that transformed the source data into an appropriate version that was written into the target. This process was facilitated by Tag Manager, which held the source and target tag configurations, allowing these special cases to be easily identified during the migration.






